[TOC]
Abs
在推测解码上做了两个事情:
1)把predictions组织成tree-based,every node represent a candidate token sequence
2)tree-based predictions可以并行verification
Intro
insight:并行猜测、树状组织、并行验证
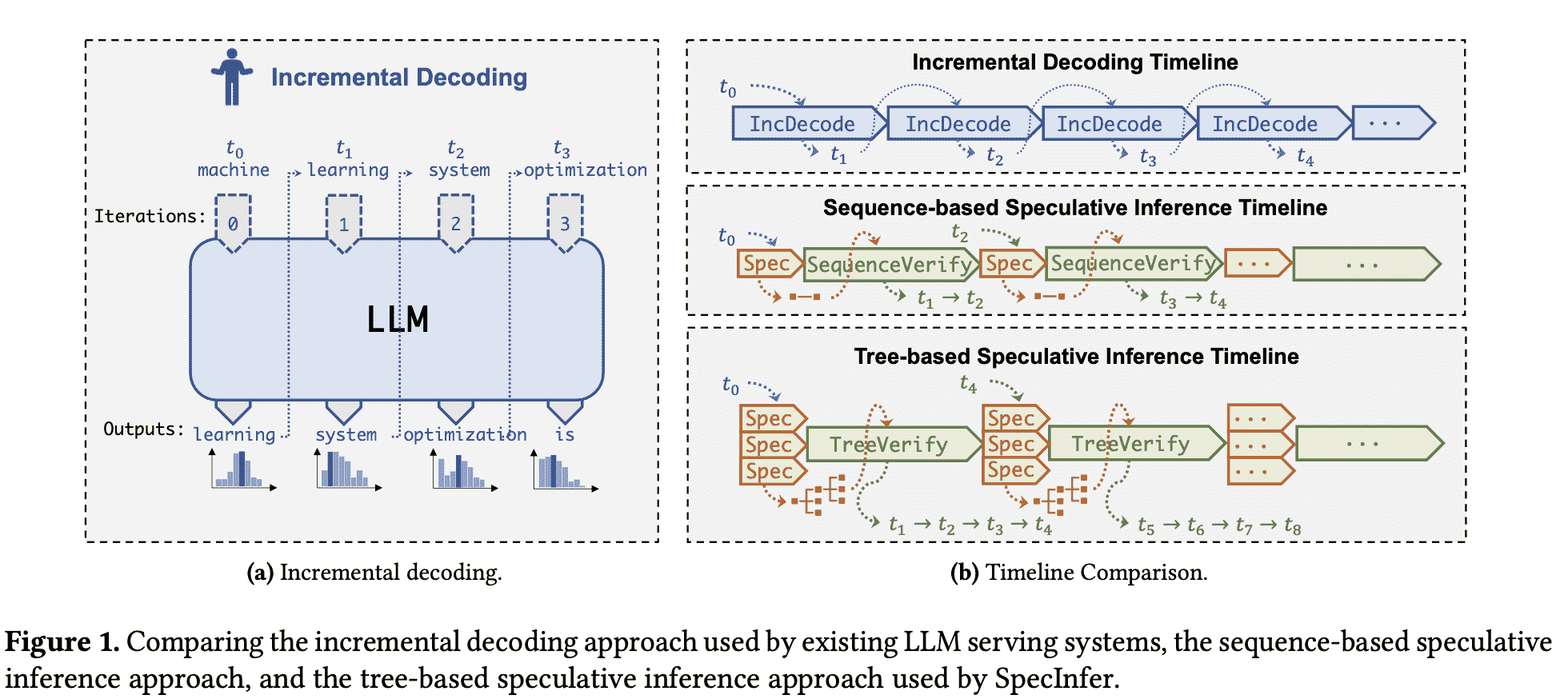
但是有两个challenge:
1)token搜索空间巨大,但是SSM和LLM之间的对齐是capacity-bound的:SpecInfer用tree组织多candidates, introduces an expansion- and a merge-based mechanism for constructing token trees by exploiting diversity within a single SSM and across multiple SSMs, respectively.
2)method of verifying the speculated tokens,要保证probability distribution一致。为了最小化验证成本,SpecInfer introduces a tree-based parallel decoding mechanism, simultaneously verifying all tokens of a token tree against the LLM’s output in a single LLM decoding step.
SpecInfer
Overview
expansion-based:就是单模型输出分支算法
merge-based:多个SSM的输出怎么合并到一棵tree中
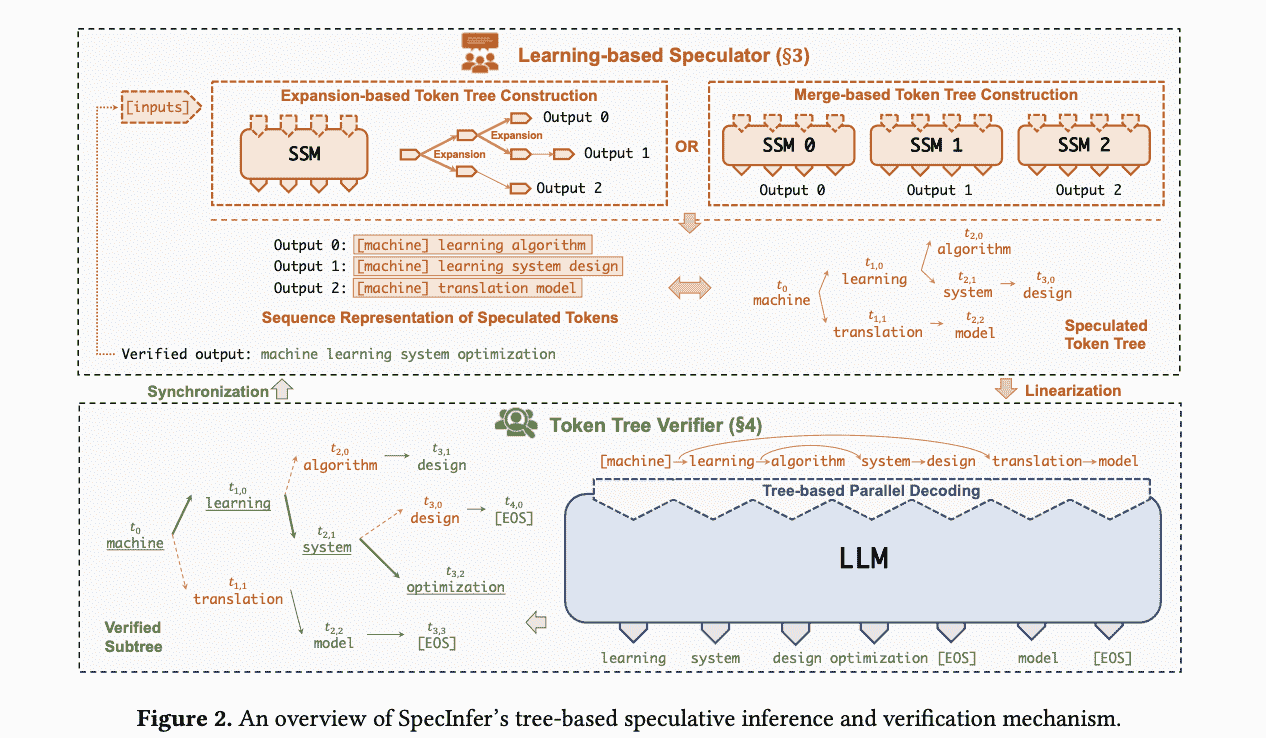
- Reduced memory accesses to LLM parameters
因为验证并行了,所以均摊下来,比起token by token方式的均摊weights访问减少了;还降低的能耗;
- Reduced end-to-end inference latency
LLM作为verfier,并行验证,并行度大大提高
Learning-based Speculator
目标:每个step多猜测一些tokens,既可以增加SSM和LLM生成overlap的比例,也可以潜在提升验证效率。
Expansion-based token tree construction
如果将speculative放在top-k上,会发现验证准确率是极速提升的:
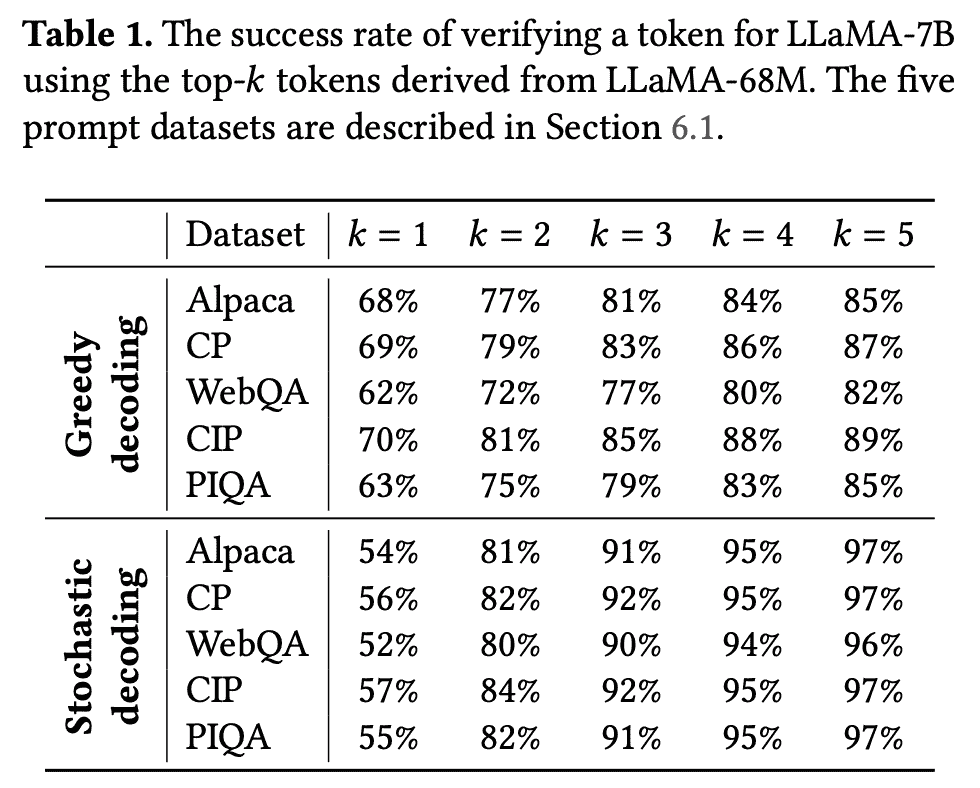
但是问题是每次选top-k的话,计算成本会exponential上升,所以作者会给一个expansion configuration: \(\left\langle k_1, k_2, \ldots, k_m\right\rangle\) 表示m步解码,每步选k_i个candidates。
怎么进行expansion仍然是future work:We acknowledge that dynamically expanding a token tree from an SSM is an opening research problem beyond the scope of this paper, which we leave as future work.
Merge-based token tree construction
这是对多个SSM输出的合并,首先SSM涉及一个distill:
1)首先有一个SSM pool,随机排列,选取第一个SSM在某一个corpus上进行distill;distill完成之后在corpus上验证,标记出不一致的。
2)选取下一个SSM,只在第一步不一致的corpus上distill,一直重复直到corpus为空
之后就进行树合并,没有特殊算法。
怎么进行集成仍然是future work:Note that, in addition to boosting, there are several other ensemble learning methods (e.g., voting, bagging, and stack- ing) that can be used to combine the outputs from multiple SSMs, and we leave the exploration as future work.
Token Tree Verifier
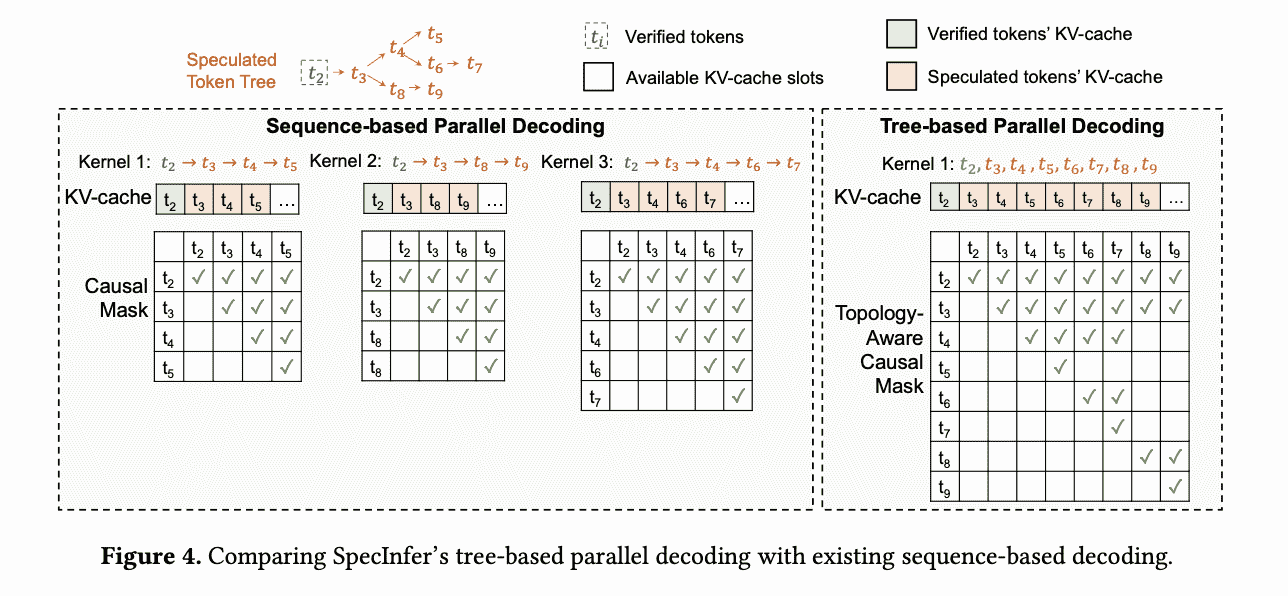
两个事情导致树结构无法并行验证,一个是KV cache重用,一个是Attention计算,这个事情十分简单,就是更新mask就可以了(但是要重写attention kernel),这样每启动一次tree attention,就只调用一次kernel。
System Implement
Distributed LLM
这里提及到SpecInfer对Distributed LLM inference的尝试,并且承认activation transfer会占用大量通信时间:Distributed LLM inference is largely limited by the latency to transfer intermediate activations between GPUs for each LLM decoding step. While SpecInfer’s ap- proach does not directly reduce the amount of inter-GPU communications, its verification mechanism can increase the communication granularity and reduce the number of decoding steps.
Exp
LLMs
LLaMA-7B, OPT- 13B, OPT-30B, and LLaMA-65B as the LLMs, and LLaMA-68M and OPT-125M as the SSMs。
Datasets
只使用prompt
We evaluate SpecInfer on five datasets: Chatbot Instruction Prompts (CIP) [34], ChatGPT Prompts (CP) [30], WebQA [1], Alpaca [36, 45], and PIQA [2]. We only use the prompts/questions from these datasets to form our input prompts to simulate real-world conversation traces.